

In the rapidly evolving world of large language models (LLMs), Google continues to push boundaries. While much attention is often focused on their largest, most powerful models, a recent release or rather, an upgrade has flown somewhat under the radar, despite its absolutely stunning performance. We’re talking about Gemini 2.5 Flash Lite, and it’s a model you seriously need to pay attention to.
The Need for Speed: Flash vs. Flash Lite
Google recently unveiled two significant updates: the latest Gemini 2.5 Flash and the new Gemini 2.5 Flash Lite. While Flash offers impressive capabilities, it’s Flash Lite that truly steals the show, especially when it comes to speed. Imagine the sensation of watching a sonic video that’s the kind of velocity we’re discussing.
Unlike models that might require specialized hardware or complex setups, Flash Lite is designed to be incredibly fast on the standard hardware Google is serving this model with. This means no more waiting for answers or experiencing frustrating delays in your applications.
Efficiency Redefined: Tokens, Latency, and Cost
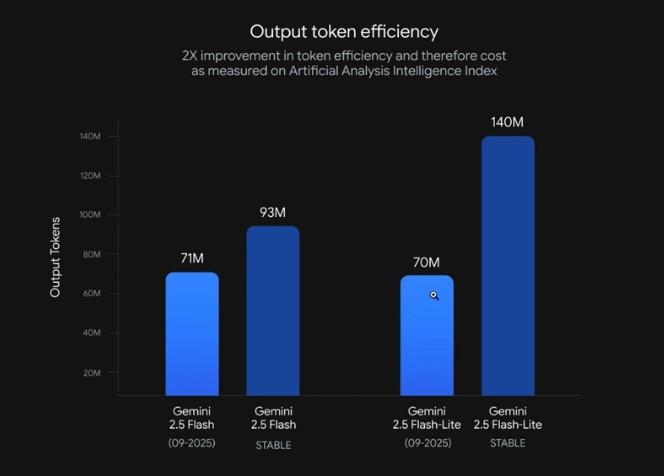
One of the most critical benchmarks for Flash Lite is its remarkable efficiency. The previous model for a particular query might have produced around 140 million output tokens. Flash Lite? It slashes that to a mere 70 million output tokens.
What does this mean for you?
- Lower Latency: Fewer output tokens translate directly to faster response times.
- Reduced Cost: Generating fewer tokens often means lower operational costs, making it ideal for applications requiring constant LLM interaction.
If you’re building an application that relies heavily on quick, continuous outputs from an LLM, this model is a worthwhile choice.
Speed Meets Intelligence: A Double Win
Often, improving speed comes at the expense of intelligence or accuracy. Not so with Flash Lite. This model has managed to decrease end-to-end response times while simultaneously maintaining, and in some cases even improving, its intelligence.
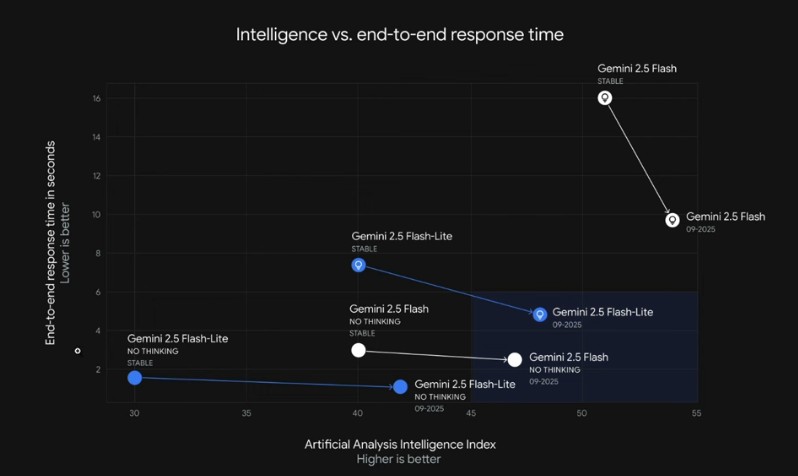
If you look at the latency-vs-intelligence chart:
- The current Gemini 2.5 Flash Lite is extremely fast, showing a lower end-to-end response time.
- It has also improved its intelligence compared to the previous Gemini 2.5 Flash.
- When compared even to the “no thinking” or “no reasoning” version of Gemini 2.5 Flash, the current 2.5 Flash Lite is much better.
The model has kept its speed (in fact, improved it) while also improving its intelligence—overall, a much better proposition.
Real-World Demos: Flash Lite in Action
To truly appreciate the difference, I ran a series of head-to-head tests using the latest Gemini 2.5 Flash and the new Gemini 2.5 Flash Lite. The goal was to see if Flash Lite’s speed gains held up across various tasks – from simple math to complex coding.
For each test, both models were given the exact same prompt and the process was timed. While both models correctly solved every problem, the contrast in response speed was dramatic.
I started with a simple, multi-step word problem:
Betty is saving money for a new wallet which costs $100. Betty has only half of the money she needs. Her parents decided to give her $15 for that purpose and her grandparents twice as much as her parents. How much more money does Betty need to buy the wallet?
| Model | Response Time (Approx.) | Result | Observation |
|---|---|---|---|
| Gemini 2.5 Flash | Slower | $5 | The model displayed a visible “thinking process” before giving the final answer. |
| Gemini 2.5 Flash Lite | Near-Instant | $5 | The response was delivered almost immediately, often before the Flash model had finished processing. |
2. Data and Programming Test: Stack Overflow Pandas Query
Next, I used a slightly more complex, real-world scenario: a recent pandas programming query posted on Stack Overflow—ensuring the exact answer wasn’t in the models’ immediate training data.
The prompt involved manipulating a DataFrame (df.groupby()…) to solve a data aggregation problem.
| Model | Response Time (Approx.) | Task Success | Observation |
|---|---|---|---|
| Gemini 2.5 Flash | Noticeably Slower | Correct Code/Output | Took its time to generate the full code block and explanation. |
| Gemini 2.5 Flash Lite | Significantly Faster | Correct Code/Output | Flash Lite completed the code generation and provided the final output well ahead of the Flash model. |
3. Accounting and Calculation Prompt
Finally, I presented a simple accounting problem that required a fractional calculation, resulting in $3.23.
| Model | Response Time (Approx.) | Result | Observation |
|---|---|---|---|
| Gemini 2.5 Flash | Slow to Start | $3.23 | Started the calculation later and trailed in completion. |
| Gemini 2.5 Flash Lite | Finished First | $3.23 | Calculated and finished the multi-step process first, proving its calculation engine is also exceptionally quick. |
In every test, both models proved their intelligence by returning the correct answers. However, Flash Lite consistently demonstrated its core advantage: it is extremely fast, providing solutions with a velocity that dramatically cuts down on end-to-end response time.
The Verdict: An Underrated Model with Huge Potential
Gemini 2.5 Flash Lite is, without a doubt, an incredibly underrated model. Its combination of unparalleled speed, lower latency, reduced cost, and maintained intelligence makes it a powerhouse for a wide range of applications.
Key Advantages:
- Blazing Fast: Significantly faster response times.
- Cost-Effective: Generates fewer tokens, leading to lower operational expenses.
- Intelligent: Maintains high levels of reasoning and accuracy.
- Versatile: Available on Google AI Studio, it can be grounded with Google Search and even read context directly from a URL.
I strongly encourage you to go try out Gemini 2.5 Flash Lite. Let me know what you think of this amazing model!